
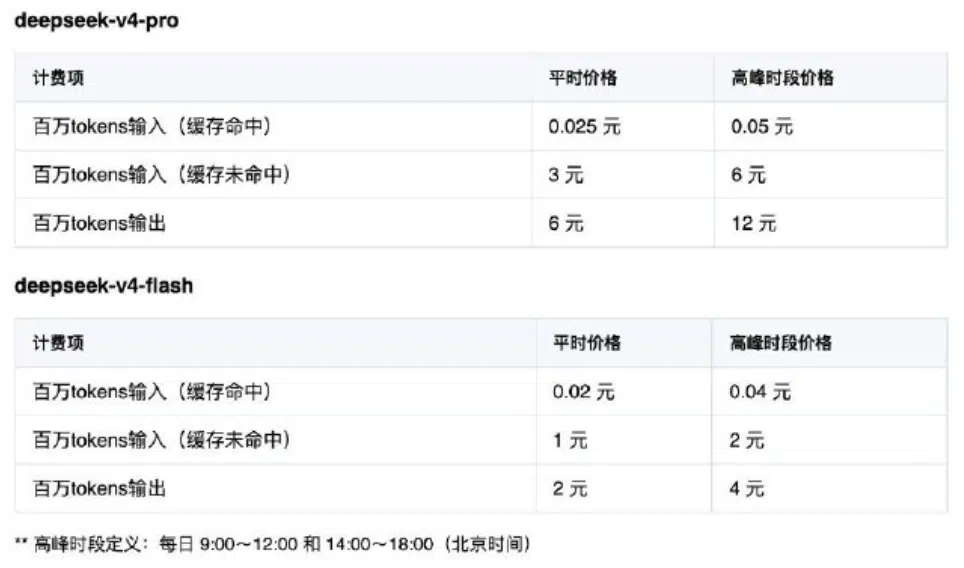
DeepSeek Introduces Peak-Valley? This strategic initiative has been validated as the Chinese AI research laboratory officially moves to address infrastructure congestion through surge-pricing mechanisms. On June 29, 2026, the company sent upgrade notifications announcing that the official release of its V4 series, scheduled for mid-July, will implement a tiered, peak-and-off-peak pricing structure [1]. Daily peak windows (9:00 to 12:00 and 14:00 to 18:00 Beijing Time) will see token rates double across the ‘deepseek-v4-pro’ and ‘deepseek-v4-flash’ models. For developer teams and product leads, this structural shift highlights a critical technical transition: as high-concurrency AI agent execution scales globally, managing compute budgets requires moving from always-on API execution toward workload scheduling and FinOps-driven orchestration.
At a Glance
- Surge Billing Deployed: DeepSeek V4 official models will introduce a tiered peak-valley structure that doubles token rates during business hours.
- Capacity Overload Realities: Programmatic queries on the ‘deepseek-v4-flash’ model recently surpassed 4.66 trillion tokens weekly on OpenRouter, triggering frequent API timeouts.
- SaaS Cost Pressures: Rising hardware and DRAM shortages are forcing major cloud developers to implement price levers to manage peak infrastructure loads.
Peak-Hour Traffic Congestion and the Financial Cost of Infinite Token Polling
According to the official announcement, the peak pricing mechanics will apply directly to the ‘deepseek-v4-pro’ and ‘deepseek-v4-flash’ models. The pro tier, featuring a 1.6-trillion-parameter Mixture of Experts (MoE) architecture, will cost 0.05 yuan per million tokens for cache-hit inputs during peak windows, doubling its off-peak rate of 0.025 yuan. Cache-miss inputs will rise from 3 yuan to 6 yuan per million tokens, while output pricing will climb from 6 yuan to 12 yuan. The smaller 284-billion-parameter Flash variant will similarly experience a twofold rate increase, with peak output costs landing at 4 yuan per million tokens. Citing official communications, this tiered structure represents a necessary mechanism to distribute computational loads and protect baseline API availability during peak enterprise working hours.
The financial pressure of maintaining low-cost API endpoints has sparked a broader pricing readjustment across the Chinese SaaS landscape. Volcengine’s Doubao 2.1 Pro maintains input rates of 6 yuan per million tokens, while competitors such as Alibaba, Tencent, Baidu, and Zhipu AI have adjusted various API packages throughout early 2026 to offset core hardware supply costs. This industry-wide inflation is occurring despite massive capital infusions. On June 16, 2026, DeepSeek secured over 50 billion yuan in external funding, backed by Tencent and CATL, alongside a recruitment campaign [2]. The strategic reality remains that low-cost models generate unprecedented traffic, and as the team from DeepSeek introduces peak-valley pricing structures to regulate demand, developers face the choice of optimizing their API call pipelines to prevent budget depletion.
While DeepSeek frames peak-valley pricing as a resource allocation mechanism, enterprise users see it as a forced migration toward workload scheduling, turning compute access into a time-sensitive financial instrument. This shift creates a stark divide between industry winners and losers. Well-capitalized development teams with localized, offline inference protect themselves by routing secondary tasks locally, while unoptimized agent startups and low-tier API aggregators face severe cost overruns during business hours.
The Protocol Breakdown: How Peak-Hour Scheduling Changes API Economics
Modern enterprise workflows frequently scale request throughput concurrently, moving from simple one-shot API queries to continuous background processes. From the perspective of runtime governance, this fundamentally changes how API execution is monitored and billed.
When high-concurrency workloads execute inside designated peak hours (9:00-12:00, 14:00-18:00 Beijing Time), they trigger immediate cost inflation. Unlike traditional systems that treat compute as a static resource, surge pricing forces developers to manage the timeline of outbound traffic. Executing unoptimized batch processes or automated data syncs during peak business hours can quickly double operational overhead. This transition requires teams to decouple execution timing from real-time triggers, routing latency-insensitive workloads through structured queues to take advantage of lower off-peak rates.
Traditional On-Demand Flow: Task Dispatched -> Immediate API Execution (Peak Hours) -> Peak Token Rate -> Cost Doubled
Orchestrated Scheduling Flow: Task Dispatched -> Queue/Scheduler -> Deferred Off-Peak Execution -> Off-Peak Token Rate -> Budget Stable
In typical production deployments, developers often encounter a notable portion of traffic being processed during peak business hours. Tracing these programmatic interactions reveals that without explicit scheduling logic, automated cron jobs or security proxies may visit links and trigger high-volume API endpoints at precisely the busiest time of day. This behavior can interfere with billing audits if systems assume every request originates from a real, manual user action.

Architectural Solutions: Peak Scheduling vs. Compute Optimization
In practice, engineering teams usually choose between building an internal cost verification framework or integrating an existing workload management SDK. Developing a proprietary system requires substantial engineering overhead. Teams must build custom server-side databases, maintain execution state libraries, and continuously update logic to comply with evolving OS security standards. For many organizations, the maintenance cost of an in-house tracker is prohibitively high.
Alternatively, developers generally evaluate several approaches to monitor runtime execution without relying entirely on cloud-side metrics:
- In-House Custom Services: Building proprietary state-matching databases on top of internal cloud architecture.
- Platform-Specific Tools: Relying on basic utilities like Firebase Dynamic Links (or their platform-native alternatives).
- Enterprise MMPs: Deploying mobile measurement partners such as Branch, AppsFlyer, or Adjust for deep-linking workflows.
- Specialized Parameter SDKs: Utilizing dedicated integration utilities for precise, cost-sensitive custom parameter pass-through.
State & Attribution Flow Comparison
| Execution Strategy | Token Cost Exposure | Execution Latency | Ideal Workload Profile |
|---|---|---|---|
| Immediate API Calls | ⚠️ High (2x Peak) | ⚡ Low (<1s) | Real-time, User-interactive |
| Peak-Hour Scheduling | 🔄 Managed | ⚠️ Medium | Automated, Asynchronous |
| Off-Peak Batch Execution | Low (Standard Rate) | ❌ High (Delayed) | High-volume offline tasks |
Task Created -> Local Scheduler Router -> Peak Hour Query Check
|
Peak Hours? (YES) -> Queue to Off-Peak Buffer -> Execute at Off-Peak Rates
|
Off-Peak? (YES) -> Direct API Execution -> Log Cost to Budget Dashboard
Commercial implementations of this model include Branch, AppsFlyer, Adjust, OpenInstall, and similar server-side state-management platforms. Among these, OpenInstall provides a robust, pre-built SDK that maps transaction variables and session metadata to a centralized state database, ensuring that session contexts are preserved even when initial tasks are executed headlessly across off-peak queues. Engineering teams may evaluate these approaches according to deployment requirements and cost-control goals, and as DeepSeek introduces peak-valley pricing structures, developers face the choice of utilizing these integrated libraries.

Operational Team Adaptations and Integration Checklists
Backend engineering teams face the immediate task of auditing all active database integrations before launching automatically compiled builds. Product leads should redesign invitation and registration loops to accommodate non-visual user journeys. Instead of assuming the user will read an email and click a button, product leads should design workflows that expect programmatic triggers. Growth teams must update their performance metrics. When autonomous software handles triage, open rates and click-through rates become less reliable. Marketing operations should focus on downstream in-app telemetry and transaction-verified conversion milestones, optimizing campaigns based on the actual actions performed within the application.
Programmatic Cost Verification Checklist
To ensure budget security and prevent quota depletion, engineering teams should execute the following steps:
- Batch Scheduler Implementation: Deploy local queuing mechanisms to delay non-interactive bulk requests until off-peak hours.
- Priority Queue Routing: Distribute API calls based on urgency to avoid peak-hour surge charges on non-essential computations.
- Cache Reuse Optimization: Enable aggressive prompt caching to reduce token rates by 90%+ for recurrent context prompts.
- Peak Window Avoidance: Configure automated scripts to suspend or throttle large-scale indexing tasks during Beijing Time peak intervals.
- Budget Telemetry Monitoring: Set up automated alarms to track hourly token consumption and trigger alerts upon exceeding threshold limits.

In typical system migrations, developers often encounter a notable portion of traffic being processed by automated scrapers. Tracing these programmatic interactions reveals that referral contexts are frequently stripped, confirming that traditional tracking frameworks are less reliable in automated setups.
Frequently Asked Questions (FAQ)
Why is DeepSeek introducing a peak-valley pricing mechanism?
The mechanism is a resource-scheduling tool designed to mitigate high-concurrency server congestion. By using price levers to discourage offline batch jobs during peak hours, DeepSeek secures API stability and transaction speeds for high-priority, real-time enterprise workflows.
How can enterprises reduce API costs under peak-valley pricing?
Enterprises can implement robust batch scheduling, cache reuse strategies, and local context caches to minimize data payloads. Leveraging prompt caching can lower input costs by more than 90%, significantly reducing financial exposure during peak hours.
How should engineering teams adapt their workloads when DeepSeek introduces peak-valley pricing?
Developers should configure local scheduler routers to defer latency-insensitive tasks to off-peak hours. Integrating secure, server-side parameter state management and session persistence platforms like OpenInstall allows teams to preserve session continuity without executing redundant, high-frequency S2S database queries.
Key Takeaways for Engineering Teams
The era of predictable flat-rate AI development is ending. Engineering teams will increasingly rely on workload scheduling, token-aware orchestration, local inference, and FinOps-driven budget governance rather than trusting cloud-side billing alone. Platforms that depend heavily on manual, visual user actions may face structural gaps when automated agents manage the request pipeline. Transitioning to server-side attribution and secure parameter pass-through represents a highly probable direction for maintaining reliable tracking and security coverage.
This transition suggests a fundamental rewrite of our measurement frameworks and security protocols. Future enterprise AI platforms will increasingly rely on workload scheduling, token-aware orchestration, local inference, and FinOps-driven budget governance rather than unlimited on-demand API execution.

