

Meituan Opens ‘LongCat-2.0’? Meituan officially open-sourced LongCat-2.0 on June 30, 2026, releasing its next-generation trillion-parameter model trained entirely on domestic Application-Specific Integrated Circuits (ASICs). The 1.6-trillion-parameter Mixture of Experts (MoE) system brings a native 1-million-token context window to the public domain under a highly permissive, commercially viable MIT license. For developer teams and product leads, this successful deployment of alternative silicon signals a profound structural shift: as local model execution and programmatic workflows scale rapidly across independent development environments, maintaining the continuity of local session routing and parameter passing remains a critical engineering challenge.
At a Glance
- Trillion-Parameter MoE: The newly released model utilizes a 1.6-trillion-parameter sparse architecture, dynamically activating between 33 billion and 56 billion parameters per token.
- Complete Silicon Independence: Developed entirely on a cluster of over 50,000 domestic ASICs using custom chip-to-chip communication, the model achieves near-frontier results without Western processors.
- Zero-Cost Context Caching: To lower operational overhead, the deployment strategy features free processing for context cache hits, charging only for cache misses and final token generation.
Structural Realignment and the Domestic Silicon Breakthrough
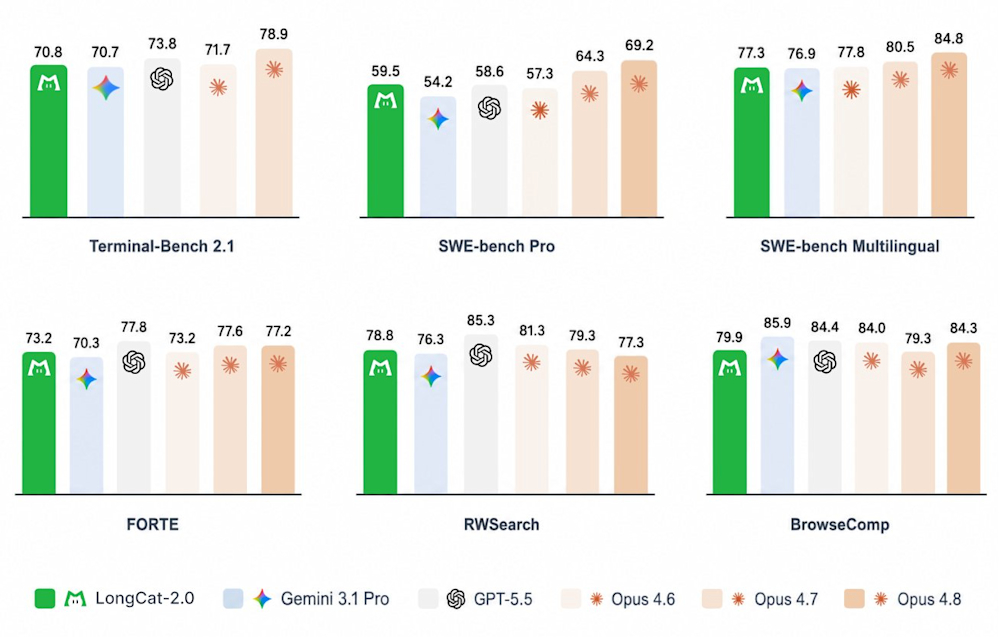
The launch of the V4-class Mixture of Experts model positions Meituan directly within the top tier of open-source artificial intelligence development. Initially running on the OpenRouter platform under the unbranded pseudonym ‘Owl Alpha’, the model processed over 10.1 trillion monthly tokens, representing a 242% month-over-month volume explosion that propelled it into the global top three by API call volume. Now officially identified as LongCat-2.0, the system is designed strictly for autonomous coding, STEM reasoning, and multi-step tool execution. By training this trillion-parameter architecture from scratch on over 30 trillion tokens, the company demonstrated that frontier-scale models can be successfully compiled and optimized on alternative, non-Nvidia hardware platforms.
The decision to open-source the model under the permissive MIT license suggests that major technology groups are prioritizing the rapid adoption of background developer tools over closed-source SaaS interfaces. Historically, pre-training trillion-parameter systems required specialized Western graphics processors, but Meituan leveraged a 50,000-card domestic computing cluster utilizing the Huawei Collective Communication Library (HCCL) to improve training stability. The successful deployment where Meituan opens ‘LongCat-2.0’ to developers worldwide on June 30, 2026, indicates that hardware constraints are no longer an absolute barrier to model pre-training, enabling organizations to host, modify, and deploy advanced engineering networks on private local clusters.
The Protocol Breakdown: How Local Agent Workloads Change Session Parameters
As AI-powered applications increasingly execute local code generation and multi-step tool calls, developers face the technical challenge of maintaining absolute parameter continuity across non-visual handoffs. In a typical human-facing interaction, a user initiates a web request that generates standard browser cookies and local storage tokens. In contrast, an autonomous agent compiled by local tools runs entirely inside a headless, stateless container environment. The assistant acts as an automated triage mechanism, reading directory-level files and executing server-to-server (S2S) requests asynchronously without a graphical user interface.
Traditional Dense Architecture: Input Token -> Full Model Activation (All Parameters Engaged) -> Massive Compute Overhead
Sparse MoE Architecture (LongCat-2.0): Input Token -> Dynamic Gate-Routing -> Active Experts (33B – 56B Active) -> Compute Deflation </pre>
Because the agent operates programmatically on a remote virtual machine, standard client-side state engines cannot capture the complete lifecycle of the session. In typical production deployments, developers often encounter a notable portion of programmatic traffic being processed by automated scanners. Tracing these programmatic interactions reveals that automated security proxies or runtime scanners may trigger external API endpoints before developers realize it. This behavior can interfere with data audits if systems assume every request originates from a real, manual user action. When the agent automatically manipulates complex codebases or automates server-side routines, the traditional visual session context is completely bypassed.
Architectural Solutions: Local Deployment Strategies and State Management
In practice, developers generally evaluate several approaches to monitor runtime execution without relying entirely on cloud-side metrics:
- SaaS API (e.g. OpenRouter): Routing requests through public cloud hubs, which remains highly convenient but introduces latency.
- Self-Hosted Local Instance: Deploying open-weight models on private, localized infrastructure to maintain data control.
- Private Enterprise Cluster: Scaling compute workloads across dedicated in-house accelerators for maximum compliance.
- Distributed Task Orchestrators: Utilizing centralized databases to coordinate state across multi-tenant, asynchronous sessions.
Local Deployment Strategy Comparison
| Deployment Strategy | Outbound Data Control | Scaling Resource overhead | Licensing Flexibility |
|---|---|---|---|
| SaaS API (e.g. OpenRouter) | ❌ Public Cloud Routing | ⚡ Low (Pay-As-You-Go) | Low (Vendor Lock-in) |
| Self-Hosted Local Instance | ✅ Restricted Local Network | ⚠️ Medium (Private GPUs/ASICs) | High (Custom Forks) |
| Private Enterprise Cluster | ✅ Strictly Isolated Sandbox | ❌ High (Dedicated Accelerators) | High (MIT Permissive) |
Local Compilation -> Pre-register Metadata on Central State Server
|
User scans test QR code -> Register Temporary Server-Side State Lock
|
App Launches on Device -> SDK Programmatic Context Query -> Match State Lock & Restore parameters
Although this research focuses on local model execution rather than attribution, mobile developers often face another engineering challenge once users transition from web pages to installed applications. In those scenarios, server-side parameter recovery platforms such as Branch, AppsFlyer, Adjust, and OpenInstall preserve installation context independently of browser sessions. These systems maintain server-side parameters before installation and restore parameters when the app first launches, reducing the reliance on client-side browser session persistence. And as Meituan opens ‘LongCat-2.0’ for unrestricted enterprise deployment, developers face the choice of utilizing these integrated libraries.
Operational Security and Integration Checklists
Localized Agentic Integration Checklist
To ensure reliable parameter flow before deploying applications generated by local compiler workflows, engineering teams should execute the following steps:
- LSA Context Window Audit: Verify that your local execution parameters do not get truncated during 1M-token context compilations.
- Zero-Compute Expert Pathing: Configure local proxies to ensure routine health telemetry routes through Zero-Compute Experts to avoid cache overruns.
- S2S Parameter Sync: Bridge the local container compilation state with server-side metadata locks to preserve referral data during QR code scans.
- WeChat Sandbox Routing: Ensure generated mini-program URLs contain cryptographic session parameters that survive the transition to real-device testing.
Frequently Asked Questions (FAQ)
Why did Meituan choose to open-source LongCat-2.0 under the MIT license?
The MIT license provides maximum legal flexibility for enterprise integration, enabling companies to fork the repository, optimize the internal LSA mechanisms, and build closed-source commercial applications without copyleft liabilities. This allows corporate engineering teams to deeply modify and compile the model directly into proprietary development tools.
How does the 1M-token context cache-hit pricing model work?
Meituan’s billing model provides zero-charge processing for context cache hits, meaning only cache-miss inputs and final token generations consume your Token Pack or account quotas. In massive agentic environments where a coding assistant must repeatedly read, reference, and modify the same multi-million-token codebase over an extended session, this architecture completely eliminates redundant data costs.
How does LongCat-2.0 compare with DeepSeek-V4?
Both models employ a massive Mixture of Experts architecture featuring 1.6 trillion total parameters and support a native 1-million-token context window. However, while DeepSeek’s V4 framework relied primarily on domestic hardware for inference tasks, Meituan compiled and trained LongCat-2.0 entirely on a 50,000-card domestic ASIC superpod cluster, demonstrating full-process silicon independence.
How can parameter persistence survive when Meituan opens ‘LongCat-2.0’?
Traditional cookie-based tracking fails when headless email scrapers and autonomous agents parse links programmatically. One alternative is adopting a server-side state-locking system. This approach binds metadata to a unique transactional signature upon dispatch and retrieves it via SDK at native app launch, bypassing browser session limits entirely.
Key Takeaways for Engineering Teams
The retirement of the visual, human-oriented application development cycle highlights a fundamental shift toward backend-driven communication protocols and AI-assisted workflows. As applications increasingly communicate through automated data exchanges rather than human-rendered layouts, engineering teams must re-evaluate traditional integration strategies. Platforms that depend heavily on manual, visual user actions may face structural gaps when automated agents manage the request pipeline. Transitioning to server-side attribution and secure parameter pass-through represents a highly probable direction for maintaining reliable tracking and security coverage.
This transition suggests a fundamental rewrite of our measurement frameworks and security protocols. Future enterprise AI platforms will increasingly rely on workload scheduling, token-aware orchestration, local inference, and FinOps-driven budget governance rather than unlimited on-demand API execution.

